
Dynamic websites use robots.txt files to regulate and control any scraping activities. These sites are protected by web scraping terms and policies to prevent bloggers and marketers from scraping their sites. For beginners, web scraping is a process of collecting data from websites and web pages and saving then saving it in readable formats.
Retrieving useful data from dynamic websites can be a cumbersome task. To simplify the process of data extraction, webmasters use robots to get the necessary information as quickly as possible. Dynamic sites comprise of 'allow' and 'disallow' directives that tell robots where scraping is allowed and where is not.
Scraping the most famous sites from Wikipedia
This tutorial covers a case study that was conducted by Brendan Bailey on scraping sites from the Internet. Brendan started by collecting a list of the most potent sites from Wikipedia. Brendan's primary aim was to identify websites open to web data extraction based on robot.txt rules. If you are going to scrape a site, consider visiting the website's terms of service to avoid copyrights violation.
Rules of scraping dynamic sites
With web data extraction tools, site scraping is just a matter of click. The detailed analysis on how Brendan Bailey classified the Wikipedia sites, and the criteria he used are described below:
Mixed
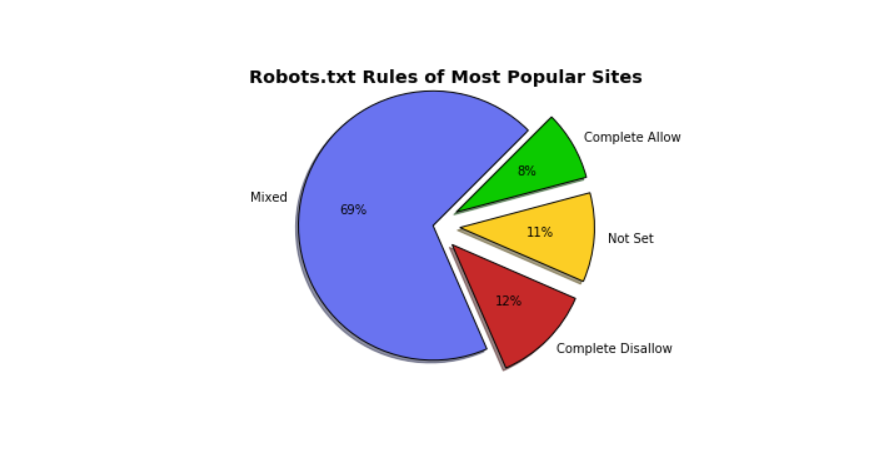
According to Brendan's case study, most popular websites can be grouped as Mixed. On the pie chart, websites with a mixture of rules represent 69%. Google's robots.txt is an excellent example of mixed robots.txt.
Complete Allow
Complete Allow, on the other hand, marks 8%. In this context, Complete Allow means that the site robots.txt file gives automated programs access to scrape the whole site. SoundCloud is the best example to take. Other examples of Complete Allow sites include:
- fc2.comv
- popads.net
- uol.com.br
- livejasmin.com
- 360.cn
Not Set
Websites with "Not Set" accounted for 11% of the total number presented on the chart. Not Set means the following two things: either the sites lack robots.txt file, or the sites lacks rules for "User-Agent." Examples of websites where the robots.txt file is "Not Set" include:
Complete Disallow
Complete Disallow sites prohibit automated programs from scraping their sites. Linked In is an excellent example of Complete Disallow sites. Other examples of Complete Disallow Sites include:
- Naver.com
- Facebook.com
- Soso.com
- Taobao.com
- T.co
Web scraping is the best solution to extract data. However, scraping some dynamic websites can land you in big trouble. This tutorial will help you to understand more about the robots.txt file and prevent problems that may occur in the future.
Post a comment