8. Fai clic con il pulsante destro del mouse per scegliere "Scrape simile... "option;
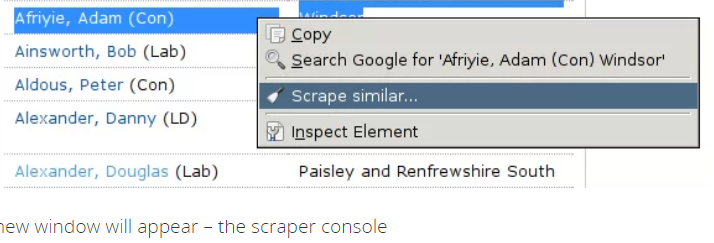
9. La console per scrapper apparirà in un'altra finestra;
10. Visualizza il contenuto raschiato nella console del raschietto;
11. Per garantire che il contenuto sia salvato come un foglio di calcolo di Google, seleziona "Salva in Google Documenti ..."
Esteso scraping
Prima di attenersi a questa ricetta, è utile capire le basi dell'HTML. Per esempio, puoi leggere una breve introduzione all'HTML tramite questo link
Immaginiamo di essere interessati a tutti i film che hanno recitato in Asia Argento, una famosa attrice italiana. 3)
1. C'è un archivio molto dettagliato di attori in IMDB Il sito di Asia Argento è: https://www.imdb.com/name/nm0000782/;
2. Qui puoi vedere tutti i ruoli interpretati dall'attrice. Iniziamo a rottamare le informazioni a cui siamo interessati;
3. Provare a grattarlo come descritto sopra;
4. Vedrete che la lista è un po 'distorta. Ciò è dovuto al fatto che l'elenco qui può essere strutturato diversamente;
5. Dirigersi verso la console del raschietto. In alto a sinistra, vedrai la piccola scatola che dice XPath;
6. Xpath è una sorta di linguaggio di query che funziona per XML e HTML;
7. XPath può aiutare a localizzare le parti della pagina che ti interessano. La prossima cosa è trovare un elemento appropriato e scrivere l'XPath per esso;
8. Ora sistemiamo il nostro tavolo;
9. Vedrete che il nostro XPath esistente, che ha tutti i dati necessari è "// div [3] / div [3] / div [2] / div";
10. XPath informa il sistema di visualizzare il documento HTML e sceglie il terzo elemento, quindi il secondo elemento e poi tutti;
11. Ma vorremmo che i nostri dati fossero separati;
12. Utilizzare la sezione colonne nella console per scrapper per ottenere questo risultato;
13. Iniziamo col trovare il titolo РІР,“ Usa Ispeziona elemento per visualizzare il titolo;
14. Controllare il titolo all'interno di un tag. Aggiungi il tag all'XPath;
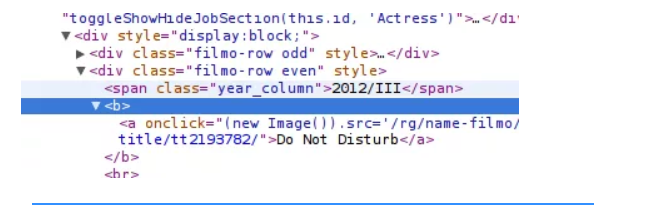
15. L'espressione sembra funzionare in modo appropriato, quindi rendi la nostra prima colonna;
16. Nella sezione "Colonne", sostituire il nome della prima colonna in "titolo";
17. Aggiungere l'XPath ad esso;
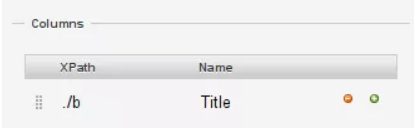
18. Nella sezione di colonna, gli XPath sono relativi e significa che "./b" sceglierà l'elemento
19. Nell'XPath per il titolo colonna, aggiungi "./b" e seleziona "scrape";
20. Ora continuiamo per un anno. Gli anni possono essere trovati entro un intervallo;
21. Creare una nuova colonna selezionando il più piccolo accanto alla colonna del titolo;
22. Usando XPath "./span" crea una colonna per "anno";
23. Fare clic su raschiare e visualizzare come è stato aggiunto l'anno;
24. Fatto!


Post a comment