Stop guessing what′s working and start seeing it for yourself.
Question Center →
Didacticiel Chrome Web Scraper de Semalt Expert


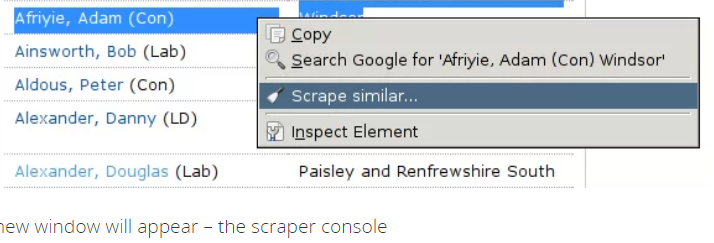
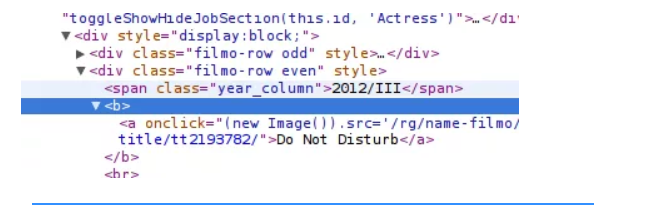
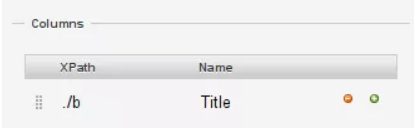
Alexander Peresunko
Laura Smith
Alexander Peresunko
Michael Johnson
Alexander Peresunko
Sarah Johnson
Alexander Peresunko
Ryan Watson
Alexander Peresunko
Emily Davis
Alexander Peresunko
David Wilson
Alexander Peresunko
Emma Roberts
Alexander Peresunko
Sophia Adams
Alexander Peresunko
Thomas Miller
Alexander Peresunko
Olivia Turner
Alexander Peresunko
Emily Davis
Alexander Peresunko
Hannah Wilson
Alexander Peresunko
Daniel Adams
Alexander Peresunko
Kate Thompson
Alexander Peresunko
Oliver White
Alexander Peresunko
Sophie Roberts
Alexander Peresunko
Lucas Martin
Alexander Peresunko
Ella Brown
Alexander Peresunko
Mia Evans
Alexander Peresunko
Sophia Thompson
Alexander Peresunko
Henry Turner
Alexander Peresunko
Nathan Cooper
Alexander Peresunko
Emma Wilson
Alexander Peresunko
Sophie Roberts
Alexander Peresunko
Lucas Wilson
Alexander Peresunko
Sophia Adams
Alexander Peresunko
Daniel Cooper
Alexander Peresunko
Emma Roberts
Alexander Peresunko
Oliver Wilson
Alexander Peresunko
Stella Davis
Alexander Peresunko
Emily Johnson
Alexander Peresunko
Thomas Wilson
Alexander Peresunko
Michael Roberts
Alexander Peresunko
Sophie Wilson
Alexander Peresunko
Ethan Thompson
Alexander Peresunko
Oliver Davis
Alexander Peresunko
Hannah Thompson
Alexander Peresunko
Mia Davis
Alexander Peresunko
David Wilson
Alexander Peresunko
Oliver Davis
Alexander Peresunko
Emily Green
Alexander Peresunko
Hannah Davis
Alexander Peresunko
Ella Johnson
Alexander Peresunko
Mia Miller
Alexander Peresunko
Thomas Green
Alexander Peresunko
Stella Jones
Alexander Peresunko
Lucas Davis
Alexander Peresunko
Sophie Adams
Alexander Peresunko
Emma Thompson
Alexander Peresunko
Alexander Peresunko
Post a comment