Stop guessing what′s working and start seeing it for yourself.
Question Center →
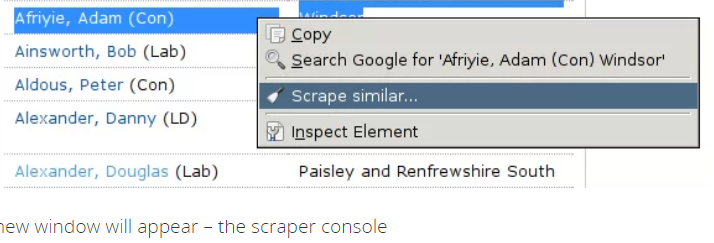
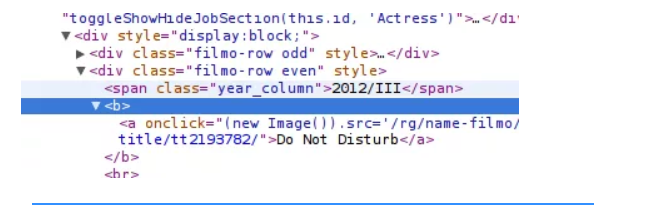
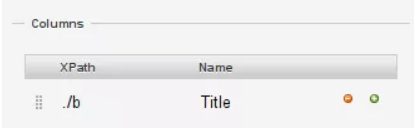
Chrome Web Scraper-zelfstudie van Semalt Expert


Sarah Wilson
Alexander Peresunko
Michael Johnson
Alexander Peresunko
Alexander Peresunko
David Adams
Alexander Peresunko
Emily Roberts
Alexander Peresunko
Daniel Harris
Alexander Peresunko
Olivia Young
Alexander Peresunko
Adam Wilson
Alexander Peresunko
Sophia Carter
Alexander Peresunko
James Brown
Alexander Peresunko
Emma King
Alexander Peresunko
Ryan Miller
Alexander Peresunko
Lily Davis
Alexander Peresunko
Noah Moore
Alexander Peresunko
Ava Wilson
Alexander Peresunko
Henry Thompson
Alexander Peresunko
Grace Harris
Alexander Peresunko
Samuel Lewis
Alexander Peresunko
Ruby Walker
Alexander Peresunko
Sebastian Johnson
Alexander Peresunko
Lucy Evans
Alexander Peresunko
Leo Wilson
Alexander Peresunko
Victoria Thompson
Alexander Peresunko
Leo Davis
Alexander Peresunko
Eva Roberts
Alexander Peresunko
Nathan Hill
Alexander Peresunko
Hannah Adams
Alexander Peresunko
Lucas Smith
Alexander Peresunko
Gabriel Brown
Alexander Peresunko
Samantha Wilson
Alexander Peresunko
Dylan Clark
Alexander Peresunko
Victoria Adams
Alexander Peresunko
Daniel Scott
Alexander Peresunko
Sophia Lewis
Alexander Peresunko
Lucy Young
Alexander Peresunko
Dylan Wilson
Alexander Peresunko
Emily Young
Alexander Peresunko
Thomas Turner
Lily Smith
Alexander Peresunko
Benjamin Harris
Alexander Peresunko
Lucas Turner
Alexander Peresunko
Sophie Jackson
Alexander Peresunko
Ethan Baker
Alexander Peresunko
Elijah Adams
Alexander Peresunko
Liam Evans
Alexander Peresunko
Brooklyn Mitchell
Alexander Peresunko
Caroline Mitchell
Alexander Peresunko
Gabriel Wilson
Alexander Peresunko
Leah Davis
Alexander Peresunko
Benjamin Clark
Alexander Peresunko
Post a comment