8. Haga clic con el botón derecho para elegir "Raspar similar..."; opción;
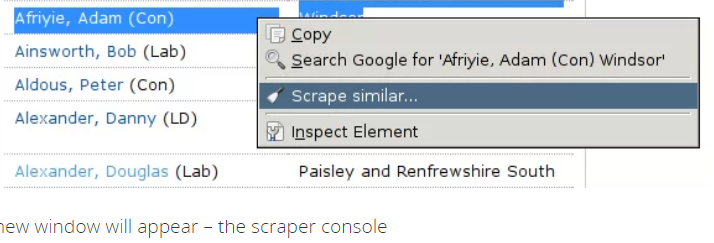
9. La consola para scrapper aparecerá en otra ventana;
10. Verá el contenido raspado en la consola del raspador;
11. Para garantizar que el contenido se guarde como una hoja de cálculo de Google, seleccione "Guardar en Google Docs..."
Raspado extendido
Antes de seguir con esta receta, es útil entender los conceptos básicos de HTML. Por ejemplo, puede leer una breve introducción al HTML a través de este enlace.
Imaginemos que estamos interesados en todas las películas protagonizadas por Asia Argento, una famosa actriz italiana.
1. Hay un archivo muy detallado de los actores en IMDB. El sitio de Asia Argento es: https://www.imdb.com/name/nm0000782/;
2. Aquí puedes ver todos los roles jugados por la actriz. Comencemos eliminando la información que nos interesa;
3. Trate de rasparlo como se describió anteriormente;
4. Verá que la lista está un poco distorsionada. Esto se debe al hecho de que la lista aquí se puede estructurar de manera diferente;
5. Dirígete a la consola del raspador. Arriba a la izquierda, verá la pequeña caja que dice XPath;
6. Xpath es un tipo de lenguaje de consulta que funciona para XML y HTML;
7. XPath puede ayudar a localizar las partes de la página que le interesan. Lo siguiente es encontrar un elemento apropiado y escribir el XPath para ello;
8. Ahora arreglemos nuestra mesa;
9. Verá que nuestro XPath existente, que tiene todos los datos necesarios, es "// div [3] / div [3] / div [2] / div";
10. XPath informa al sistema para ver el documento HTML y elige el tercer elemento, luego el segundo elemento y luego todos;
11. Pero nos gustaría separar nuestros datos;
12. Utilice la sección de columnas en la consola para scrapper para hacer esto;
13. Primero busquemos nuestro título РІР,“ Use Examinar elemento para ver el título;
14. Verifique el título dentro de una etiqueta. Agregue la etiqueta a XPath;
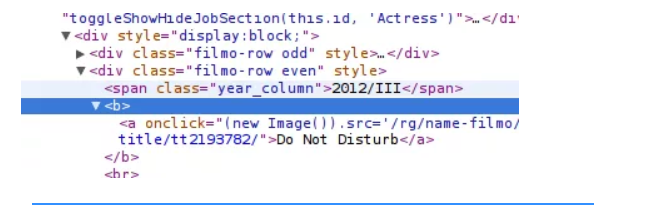
15. La expresión parece funcionar apropiadamente, así que conviértalo en nuestra primera columna;
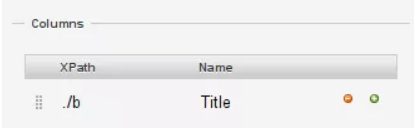
16. En la sección "Columnas", reemplace el nombre de la primera columna por "título";
17. Agregue el XPath a él;
18. En la sección de la columna, los XPaths son relativos y significa que "./b" elegirá el elemento
19. En el XPath para el título columna, agregue "./b" y seleccione "raspar";
20. Ahora sigamos por un año. Los años se pueden encontrar en un lapso de tiempo;
21. Cree una nueva columna seleccionando el pequeño más al lado de la columna para su título;
22. Usando XPath "./span" crea una columna para "año";
23. Haga clic en raspar y vea cómo se agregó el año;
24. ¡Hecho!


Post a comment