Stop guessing what′s working and start seeing it for yourself.
Question Center →
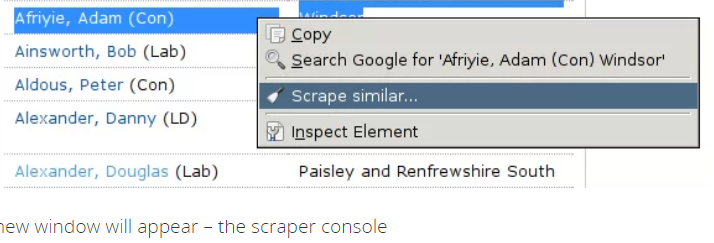
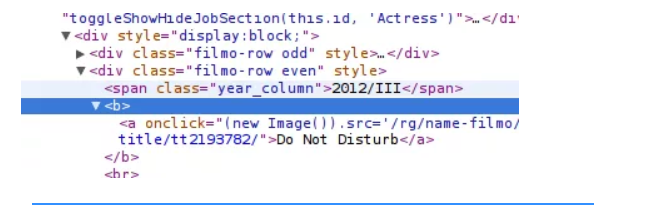
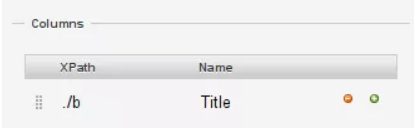
Chrome Web Scraper Tutorial From Semalt Expert


Jessica
Sarah
Mark
Julia
Emily
David
Michael
Daniel
Alexander Peresunko
Jessica
Sarah
Emily
Michael
David
Sarah
Mark
Julia
James
Olivia
Mark
Jessica
Michael
David
Julia
Mark
Emily
David
Jessica
Sarah
Olivia
Julia
Mark
Olivia
Mark
Emily
David
Jessica
Sarah
Olivia
Mark
Emily
David
Jessica
Michael
Sarah
Olivia
Mark
Emily
David
Jessica
Sarah
Michael
Olivia
Michael
Alexander Peresunko
Sarah
Olivia
Alexander Peresunko
Mark
Emily
David
Sarah
Alexander Peresunko
Emily
David
Olivia
Sarah
Alexander Peresunko
Emily
Peter
Lisa
Alexander Peresunko
Rachel
Michael
Alexander Peresunko
Julia
David
Alexander Peresunko
Sarah
Emily
Alexander Peresunko
Olivia
Mark
Alexander Peresunko
Daniel
Jessica
Alexander Peresunko
Michael
Alexander Peresunko
David
Alexander Peresunko
Sarah
Alexander Peresunko
Olivia
Alexander Peresunko
Julia
Alexander Peresunko
Post a comment