
Sites dinâmicos usam arquivos robots.txt para regular e controlar quaisquer atividades de raspagem. Esses sites são protegidos por termos e políticas de raspagem na web para impedir que blogueiros e comerciantes raspe seus sites. Para iniciantes, a raspagem na Web é um processo de coleta de dados de sites e páginas da web e salvar, em seguida, salvá-lo em formatos legíveis.
Recuperar dados úteis de sites dinâmicos pode ser uma tarefa incômoda. Para simplificar o processo de extração de dados, os webmasters usam robôs para obter as informações necessárias o mais rápido possível. Os sites dinâmicos compõem as diretivas "permitir" e "desautorizar" que dizem aos robôs onde a raspagem é permitida e onde não é.
Raspando os sites mais famosos da Wikipédia
Este tutorial cobre um estudo de caso que foi realizado por Brendan Bailey em sites de raspagem da Internet. Brendan começou coletando uma lista dos sites mais potentes da Wikipedia. O principal objetivo da Brendan era identificar sites abertos para a extração de dados da Web com base nas regras do robot.txt. Se você estiver raspando um site, considere visitar os termos de serviço do site para evitar violação de direitos autorais.
Regras de raspagem de sites dinâmicos
Com ferramentas de extração de dados na web, a raspagem do site é apenas uma questão de clique. A análise detalhada de como Brendan Bailey classificou os sites de Wikipedia e os critérios que utilizou estão descritos abaixo:
Misturado
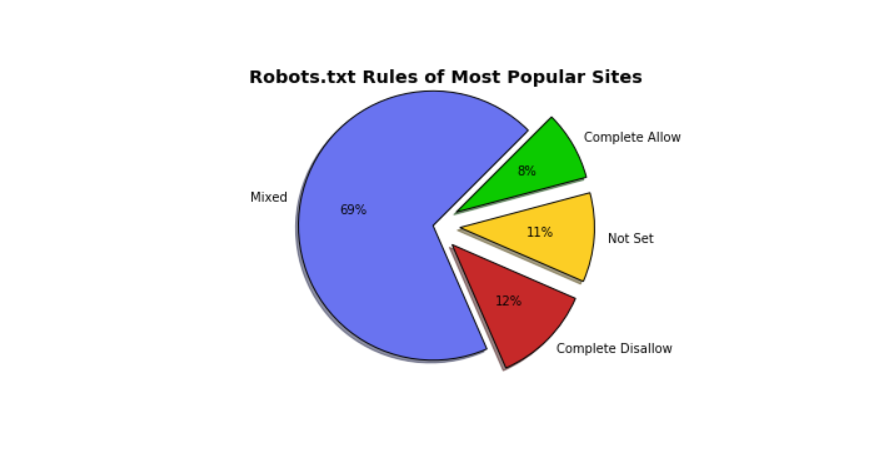
De acordo com o estudo de caso de Brendan, os sites mais populares podem ser agrupados como Misturados. No gráfico de torta, os sites com uma mistura de regras representam 69%. O robots.txt do Google é um excelente exemplo de robots.txt mistos.
Complete Allow
Complete Allow, por outro lado, marca o 8%. Neste contexto, Complete Allow significa que o arquivo robots.txt do site dá acesso a programas automatizados para raspar todo o site. O SoundCloud é o melhor exemplo a ser utilizado. Outros exemplos de sites de Permitir completo incluem:
- fc2.comv
- popads.net
- uol.com.br
- livejasmin.com
- 360.cn
Não definido
Os sites com "Não definido" representaram 11% do número total apresentado no gráfico. Não definido significa as seguintes duas coisas: os sites não possuem o arquivo robots.txt ou os sites carece de regras para "User-Agent". Exemplos de sites onde o arquivo robots.txt é "Not Set" incluem:
Complete Disallow
Complete Disallow sites proíbem programas automatizados de raspagem seus sites. Linked In é um excelente exemplo de sites completos de desativação. Outros exemplos de sites completos de desativação incluem:
- Naver.com
- Facebook.com
- Soso.com
- Taobao.com
- T.co
A raspagem da Web é a melhor solução para extrair dados. No entanto, raspar alguns sites dinâmicos pode pousá-lo em grandes problemas. Este tutorial irá ajudá-lo a entender mais sobre o arquivo robots.txt e evitar problemas que possam ocorrer no futuro.

Post a comment