8. "Scrape Benzer: "seçeneği;
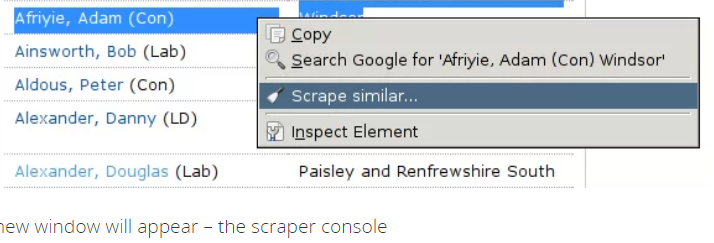
9. Scrapper konsolu başka bir pencerede açılır;
10. Kazıyıcıdaki kazıyıcıdaki içeriği görüntüleyin
11. İçeriğin bir Google E-tablosu olarak kaydedildiğinden emin olmak için "Google Dokümanlar'a Kaydet ..." seçeneğini seçin.
Uzatılmış kazıma
Bu tarifi yapıştırmadan önce , HTML temellerini anlamakta fayda vardır.Örneğin, bu linki ile HTML'ye kısa bir giriş okuyabilirsiniz
Asya Argento'nun başrolünü oynadığı tüm filmlerle ilgilendiğimizi düşünelim, Ünlü bir İtalyan aktrist.
1. IMDB'de aktörlerin çok detaylı bir arşivi var: Asia Argento sitesi: https://www.imdb.com/name/nm0000782/;
2. Burada, oyuncu tarafından oynanan tüm rolleri görebilirsiniz. İlgilendiğimiz bilgileri silmeye başlayalım;
3. Yukarıda anlatıldığı şekilde sıyırmaya çalışın;
4. Listenin biraz bozuk olduğunu görürsünüz. Bunun nedeni, buradaki listenin farklı şekilde yapılandırılabilmesidir;
5. Sıyırıcı konsoluna yönelin. Sol üstte, XPath diyen küçük kutuyu göreceksiniz;
6. Xpath, XML ve HTML için çalışan bir sorgu dili türüdür;
7. XPath, ilgilendiğiniz sayfanın bölümlerini bulmanıza yardımcı olabilir. Sonraki şey, uygun bir öğe bulmak ve bunun için XPath yazmaktır;
8. Şimdi masamızı ayarlayalım;
9. Gerekli tüm verilere sahip olan mevcut XPath'ımız "// div [3] / div [3] / div [2] / div";
10. XPath, Sistemi HTML dokümanını görüntüleyecek ve üçüncü unsuru, daha sonra ikinci unsuru ve hepsini seçecek şekilde bilgilendirir;
11. Ancak, verilerimizi ayrıştırmak istiyoruz;
12. Bu işi halletmek için scrapper'ın konsolundaki sütun bölümünden yararlanın;
13. İlk başlığımızı bulalım RESİMLERİ Başlığı görüntülemek için İnceleme Öğesini Kullan;
14. Bir etiket içindeki başlığı kontrol edin. Etiketi XPath'a ekleyin;
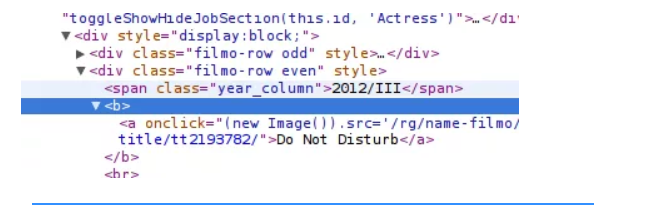
15. İfade uygun şekilde işliyormuş gibi görünür;
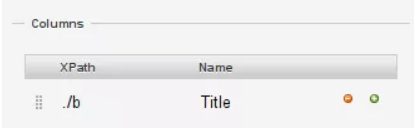
16. "Sütunlar" bölümünde, ilk sütunun adını "başlık" olarak değiştirin;
17.Buna XPath ekleyin; 18. Kolon bölümünde, XPath'ler görecelidir ve "./b" başlık sütununa "./b" ekleyin ve "kazıma" yı seçin;
18. Kolon bölümünde, XPath'ler görecelidir ve "./b" başlık sütununa "./b" ekleyin ve "kazıma" yı seçin;
20. Şimdi bir yıllığına devam edelim. Yıllar bir süre içerisinde bulunabilir;
21. Başlıkınızın sütununun yanındaki küçük artı işaretini seçerek yeni bir sütun oluşturun;
22. XPath'ı kullanarak "./span" "yıl" için bir sütun oluşturun;
23. Kazıma üzerine tıklayın ve yılın nasıl eklendiğini görün;
24. Bitti!

Post a comment