
Les sites dynamiques utilisent des fichiers robots.txt pour réguler et contrôler les activités de grattage. Ces sites sont protégés par termes et politiques de scrapbooking pour empêcher les blogueurs et les spécialistes du marketing d'égratigner leurs sites. Pour les débutants, le web scraping est un processus de collecte de données à partir de sites Web et de pages Web et de l'enregistrement, puis de l'enregistrer dans des formats lisibles.
Récupérer des données utiles à partir de sites Web dynamiques peut être une tâche fastidieuse. Pour simplifier le processus d'extraction des données, les webmasters utilisent des robots pour obtenir les informations nécessaires le plus rapidement possible. Les sites dynamiques comprennent des directives 'allow' et 'disallow' qui indiquent aux robots où le raclage est autorisé et où ne l'est pas.
Scraping des sites les plus célèbres de Wikipédia
Ce tutoriel couvre une étude de cas menée par Brendan Bailey sur des sites de grattage d'Internet. Brendan a commencé par recueillir une liste des sites les plus puissants de Wikipédia. L'objectif principal de Brendan était d'identifier les sites Web ouverts à l'extraction de données Web en se basant sur les règles de robot.txt. Si vous souhaitez graver un site, pensez à consulter les conditions d'utilisation du site pour éviter toute violation des droits d'auteur.
Règles de grattage des sites dynamiques
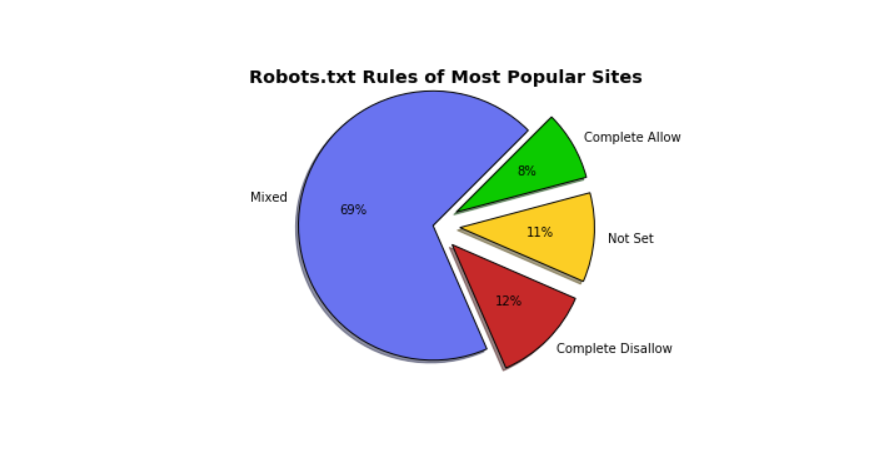
Avec les outils d'extraction de données Web, le grattage du site est juste une question de clic. L'analyse détaillée de la classification des sites de Wikipédia par Brendan Bailey et les critères qu'il utilise sont décrits ci-dessous:
Mixed
Selon l'étude de Brendan, les sites les plus populaires peuvent être regroupés. Sur le camembert, les sites Web avec un mélange de règles représentent 69%. Le fichier robots.txt de Google est un excellent exemple de robots.txt mixtes.
Achever Autoriser
Accepter Autoriser, d'autre part, Dans ce contexte, Complete Allow signifie que le fichier robots.txt du site donne accès aux programmes automatisés pour racler l'ensemble du site, SoundCloud est le meilleur exemple à suivre.Autres exemples de sites complets autorisés:
- fc2.comv
- popads.net
- uol.com.br
- livejasmin.com
- 360.cn
Non défini
Les sites Web avec "Non défini" représentaient 11% du nombre total présenté sur le graphique.Non défini signifie les deux choses suivantes: soit les sites manquent de fichier robots.txt, soit les sites manque de règles pour "User-Agent." Exemples de sites Web où le fichier robots.txt est "Not Set" comprennent:
Disallow complet
Les sites interdits complets interdisent le raclage de programmes automatisés leurs sites. Linked In est un excellent exemple de sites complets Disallow. Voici d'autres exemples de sites interdits complets:
- Naver.com
- Facebook.com
- Soso.com
- Taobao.com
- T.co
Web scraping est la meilleure solution pour extraire des données. Cependant, gratter certains sites Web dynamiques peut vous poser de gros problèmes. Ce tutoriel vous aidera à mieux comprendre le fichier robots.txt et à prévenir les problèmes qui pourraient survenir dans le futur.
Post a comment