8. Klicken Sie mit der rechten Maustaste, um "Scrape Simply" auszuwählen. . "Option;
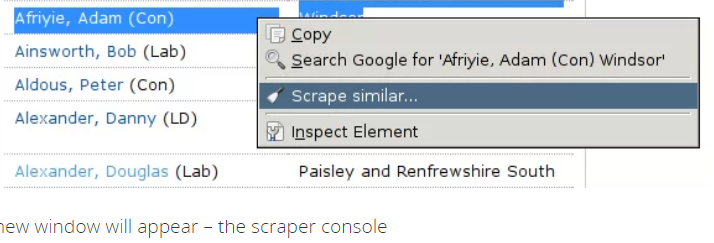
9. Die Konsole für den Scrapper wird in einem anderen Fenster angezeigt;
10. Sehen Sie den abgekratzten Inhalt in der Scraper-Konsole an;
11. Um sicherzustellen, dass der Inhalt als Google Spreadsheet gespeichert wird, wählen Sie "In Google Docs speichern ...".
Erweitertes Scraping
Bevor Sie sich an dieses Rezept halten, ist es nützlich zu verstehen Die Grundlagen von HTML, zum Beispiel, können Sie eine kurze Einführung in HTML über diesen Link lesen .
Stellen wir uns vor, wir interessieren uns für alle Filme, in denen Asia Argento, eine berühmte italienische Schauspielerin, zu sehen war.
1. Es gibt ein sehr detailliertes Archiv von Akteuren in der IMDB: Die Website von Asia Argento lautet: https://www.imdb.com/name/nm0000782/;
2. Hier können Sie alle Rollen der Schauspielerin sehen. Beginnen wir mit der Verschrottung der Informationen, an denen wir interessiert sind;
3. Versuche es so zu kratzen, wie es oben beschrieben wurde;
4. Sie werden sehen, dass die Liste ein wenig verzerrt ist. Dies liegt daran, dass die Liste hier anders strukturiert sein kann;
5. Gehen Sie zur Schaberkonsole. Oben links siehst du die kleine Box mit XPath;
6. Xpath ist eine Art Abfragesprache, die für XML und HTML arbeitet;
7. XPath kann helfen, die Teile der Seite zu finden, an denen Sie interessiert sind. Als nächstes müssen Sie ein geeignetes Element finden und den XPath dafür schreiben;
8. Jetzt lasst uns unseren Tisch arrangieren;
9. Sie werden sehen, dass unser existierender XPath, der alle benötigten Daten enthält, "// div [3] / div [3] / div [2] / div" ist;
10. XPath informiert das System, das HTML-Dokument anzuzeigen und wählt das dritte Element, dann das zweite Element und dann alle aus;
11. Wir möchten jedoch, dass unsere Daten getrennt werden;
12. Nutzen Sie den Spaltenbereich in der Konsole für Scrapper, um dies zu erledigen;
13. Lassen Sie uns zuerst unseren Titel finden РІР,в Verwenden Sie Inspect Element, um den Titel anzuzeigen;
14. Überprüfen Sie den Titel innerhalb eines Tags. Fügen Sie das Tag zum XPath hinzu;
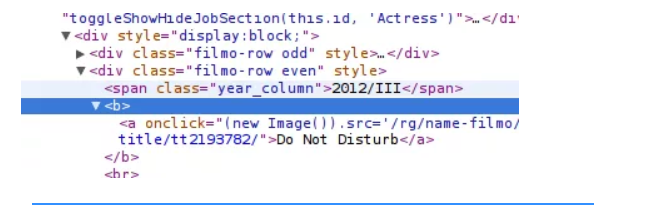
15. Der Ausdruck scheint angemessen zu funktionieren, also machen Sie es zu unserer ersten Spalte;
16. Ersetzen Sie im Abschnitt "Spalten" den Namen der ersten Spalte durch "Titel";
17. Fügen Sie den XPath hinzu;
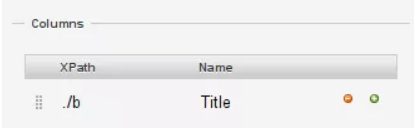
18. Im Spaltenabschnitt sind die XPaths relativ und es bedeutet, dass "./b" das Element
wählt. 19. Im XPath für den Titel Spalte, füge "./b" hinzu und wähle "scrape";
20. Lass uns jetzt ein Jahr weitermachen. Jahre können innerhalb einer Spanne gefunden werden;
21. Erstellen Sie eine neue Spalte, indem Sie das kleine Pluszeichen neben der Spalte für Ihren Titel auswählen.
22. Erstellen Sie mit XPath "./span" eine Spalte für "Jahr";
23. Klicken Sie auf Kratzen und sehen Sie, wie das Jahr hinzugefügt wurde;
24. Fertig!


Post a comment