8. Clique com o botão direito do mouse para escolher o "Raspar Similar ... . "opção;
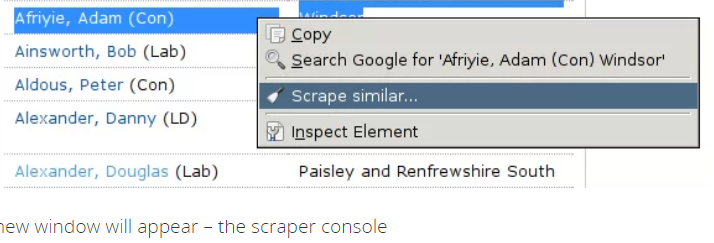
9. O console do scrapper aparecerá em outra janela;
10. Visualize o conteúdo raspado na consola raspadora;
11. Para garantir que o conteúdo seja salvo como Google Spreadsheet, selecione "Salvar no Google Docs ..."
Raspagem prolongada
Antes de aderir a esta receita, é útil entender O básico do HTML. Por exemplo, você pode ler uma breve introdução ao HTML através deste link.
Imaginemos que estamos interessados em todos os filmes que estrelaram a Asia Argento, uma famosa atriz italiana.
1. Existe um arquivo muito detalhado de atores na IMDB. O site Asia Argento é: https://www.imdb.com/name/nm0000782/;
2. Aqui, você pode ver todos os papéis desempenhados pela atriz. Vamos começar a desfazer as informações que nos interessam;
3. Tente esvaziá-lo da maneira como foi descrito acima;
4. Você verá que a lista está um pouco distorcida. Isso se deve ao fato de que a lista aqui pode ser estruturada de forma diferente;
5. Dirija-se ao console do raspador. Superior esquerdo, você verá a pequena caixa que diz XPath;
6. Xpath é um tipo de linguagem de consulta que funciona para XML e HTML;
7. O XPath pode ajudar a localizar as partes da página em que está interessado. A próxima coisa é encontrar um elemento apropriado e escrever o XPath para ele;
8. Agora vamos organizar nossa mesa;
9. Você verá que nosso XPath existente, que possui todos os dados necessários é "// div [3] / div [3] / div [2] / div";
10. O XPath informa o Sistema para ver o documento HTML e escolher o terceiro elemento, depois o segundo elemento e depois todos eles;
11. Mas, gostaríamos que nossos dados fossem separados;
12. Utilize a seção de colunas no console para scrapper para fazer isso;
13. Vamos primeiro encontrar o nosso título РІР - Usar Inspect Element para ver o título;
14. Verifique o título dentro de uma etiqueta. Adicione a tag ao XPath;
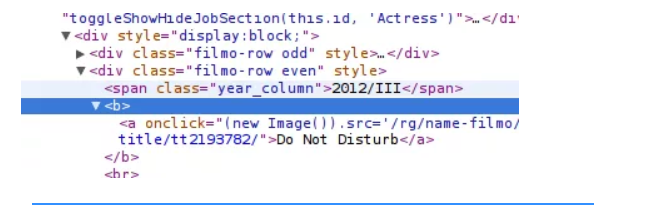
15. A expressão parece funcionar adequadamente, então faça da nossa primeira coluna;
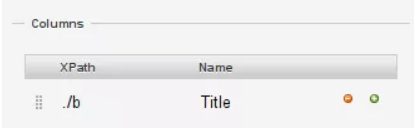
16. Na seção "Colunas", substitua o nome da primeira coluna por "título";
17. Adicione o XPath a ele;
18. Na seção de coluna, os XPaths são relativos e isso significa que "./b" escolherá o elemento
19. No XPath para o título coluna, adicione "./b" e selecione "raspar";
20. Agora vamos continuar por um ano. Os anos podem ser encontrados dentro de um período;
21. Crie uma nova coluna selecionando a pequena vantagem ao lado da coluna para o seu título;
22. Usando o XPath "./span", crie uma coluna para "ano";
23. Clique em raspar e ver como o ano foi adicionado;
24. Feito!


Post a comment