
Dynamische Websites verwenden robots.txt-Dateien zur Regulierung und Kontrolle von Scraping-Aktivitäten. Diese Websites sind durch Web Scraping Bedingungen und Richtlinien geschützt, um zu verhindern, dass Blogger und Vermarkter ihre Websites scrapen. Für Anfänger ist Web Scraping ein Prozess der Sammlung von Daten von Websites und Webseiten und Speichern und Speichern in lesbaren Formaten.
Das Abrufen nützlicher Daten von dynamischen Websites kann eine mühsame Aufgabe sein. Um den Prozess der Datenextraktion zu vereinfachen, verwenden Webmaster Roboter, um die erforderlichen Informationen so schnell wie möglich zu erhalten. Dynamische Sites umfassen "Zulassen" - und "Nicht zulassen" -Direktiven, die Robotern mitteilen, wo Scrapping erlaubt ist und wo nicht.
Scraping der berühmtesten Seiten aus Wikipedia
Dieses Tutorial behandelt eine Fallstudie, die von Brendan Bailey auf Scraping-Seiten aus dem Internet durchgeführt wurde. Brendan begann damit, eine Liste der mächtigsten Seiten von Wikipedia zu sammeln. Das Hauptziel von Brendan bestand darin, Websites zu identifizieren, die für die Datenextraktion auf der Grundlage der robot.txt-Regeln offen sind. Wenn Sie eine Website scrappen möchten, sollten Sie die Nutzungsbedingungen der Website beachten, um Verstöße gegen die Urheberrechte zu vermeiden.
Regeln zum Scraping von dynamischen Sites
Mit Web-Datenextraktionswerkzeugen ist Site Scraping nur eine Frage des Klicks. Die detaillierte Analyse, wie Brendan Bailey die Wikipedia-Seiten und die von ihm verwendeten Kriterien klassifizierte, wird im Folgenden beschrieben:
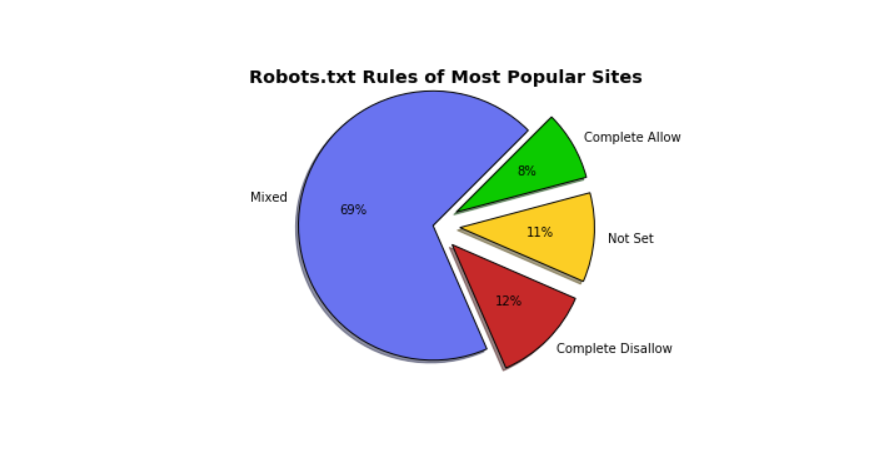
Mixed
Laut Brendans Fallstudie können die beliebtesten Websites als Mixed gruppiert werden. Im Tortendiagramm repräsentieren Websites mit einer Mischung von Regeln 69%. Googles robots.txt ist ein hervorragendes Beispiel für eine gemischte robots.txt.
 Erlaube vollständig
Erlaube vollständig
Erledige Erlaube auf der anderen Seite, In diesem Kontext bedeutet Complete Allow, dass die Site robots.txt-Datei automatisierten Programmen Zugriff gewährt, um die gesamte Site zu scratzen.SoundCloud ist das beste Beispiel dafür. Weitere Beispiele für Complete Allow-Sites sind:
- fc2.comv
- popads.de
- uol.com.br
- livejasmin.com
- 360.cn
Nicht festgelegt
Websites mit "Nicht festgelegt" entfielen 11% der Gesamtzahl auf dem Diagramm dargestellt. Nicht festgelegt bedeutet die folgenden zwei Dinge: entweder die Websites robots.txt-Datei oder die Websites Es fehlen Regeln für "User-Agent". Beispiele für Websites, auf denen die robots.txt-Datei "Nicht festgelegt" ist, sind:
Komplette Disallow
Complete Disallow-Seiten verbieten automatisierten Scraping-Programmen ihre Seiten. Linked In ist ein hervorragendes Beispiel für Complete Disallow-Sites. Andere Beispiele für Komplette Disallow Sites sind:
- Naver.com
- Facebook.com
- Soso.com
- Taobao.com
- T.co
Web Scraping ist die beste Lösung, um Daten zu extrahieren. Wenn Sie jedoch einige dynamische Websites scrapen, können Sie große Probleme bekommen. Dieses Tutorial hilft Ihnen, mehr über die robots.txt-Datei zu erfahren und Probleme zu vermeiden, die in Zukunft auftreten können.
Post a comment